Led by biochemist David Hendrix, Oregon State researchers have developed a computer program that represents a key step toward better understanding the connections between mutant genetic material and disease.
Known as bpRNA, the software is a big-data annotation tool for secondary structures in ribonucleic acids. The paper was published this month in Nucleic Acids Research.
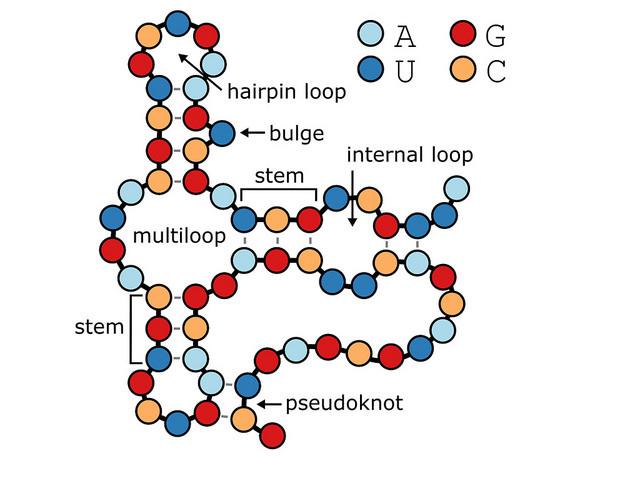
“It’s capable of parsing RNA structures, including complex pseudoknot-containing RNAs, so you end up with an objective, precise, easily-interpretable description of all loops, stems and pseudoknots,” said corresponding author Hendrix, an assistant professor with joint appointments in biochemistry and biophysics and computer science.
“You also get the positions, sequence and flanking base pairs of each structural feature, which enables us to study RNA structure en masse at a large scale.”
RNA works with DNA, the other nucleic acid – so named because they were first discovered in the cell nuclei of living things – to produce the proteins needed throughout the body. DNA contains a person’s hereditary information, and RNA delivers the information’s coded instructions to the protein-manufacturing sites within the cells. Many RNA molecules do not encode a protein, and these are known as noncoding RNAs.